

AI Innovation Leaders Building Custom LLM ‘Backbones’
The backbones can be subsets of pretrained, fine-tuned models focused on specific tasks such as language generation or reading comprehension.

By John P. Desmond, Editor, AI in Business
Today’s leading AI innovating companies are constructing united AI “backbones” of large language models (LLMs) for natural language processing that are serving as a foundation for the next five to 10 years of AI application development and deployment in their organizations.
“We’re seeing that with those taking a leadership position, starting with the hyperscale, cloud services providers who have done this on a massive scale,” stated Marshall Choy, senior VP of product at SambaNova, which offers dataflow-as-a-service, in a recent issue of VentureBeat

Soon, he suggested, it will be “unheard of” for enterprises not to have an LLM-based AI “backbone.” Companies that commit to doing that now, will derive benefits in the long term, he suggested. Organizations that are earlier on the AI maturity curve, are engaged in self-educating, experimenting and doing pilots to try to determine the right use cases for AI.
“Those folks are a long way from enterprise-scale adoption,” stated Choy. Organizations further up the curve are deploying AI in departments and are beginning to reach a later stage. “They’ve got architectural and data maturity; they’re starting to standardize on platforms; they have budgets,” Choy stated.
Banks exploring AI typically have many separate models running in the enterprise. With foundation models of GPT-3 now available, these organizations are in a position to make big-picture AI investments, leading to more customized services for their users.
“The banking industry is at the stage where there’s a recognition that AI is going to be the accelerant for the next transitional shift for the enterprise,” Choy stated.
Advances in language models are making it possible to pursue deep learning efforts with LLMs and language processing, which underlie much of the AI development activity in banking, insurance, warehousing and logistics. “No industry will be untouched,” Choy stated. “Language is the connector to everything that we do.”
The ability of the LLMs to generate text for meeting transcripts, and for claims processing and completion, is a huge step forward for front and back offices.
LLM Options Emerging
The availability of different types of LLMs is presenting AI developers with more options.
“Large models are used for zero-shot scenarios or few-shot scenarios where little domain-[tailored] training data is available and usually work okay, generating something based on a few prompts,” stated Fangzheng Xu, a Ph.D. student at Carnegie Mellon specializing in natural language processing, in a recent account in Techcrunch. A “few-shot” scenario refers to training a model with minimal data; a “zero-shot” scenario refers to a model that can learn to recognize things it has not explicitly seen during training.
“A single large model could potentially enable many downstream tasks with little training data,” Xu stated.
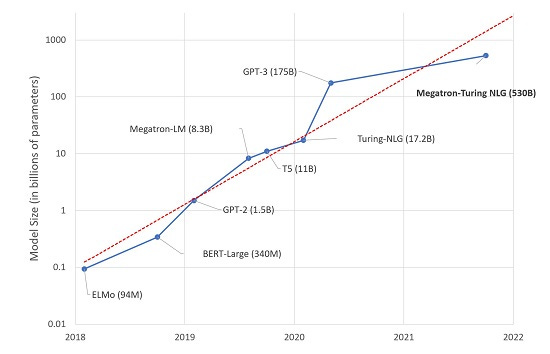
To review recent LLM history, in June 2020, OpenAI released GPT-3, a model with 175 billion parameters that can generate text and code given a short prompt with instructions. EleutherAI, an open research group, later released GPT-J, a smaller LLM with six billion parameters, that can translate between languages, write blog posts and complete code. Recently, Microsoft and Nvidia released a model via open source named Megatron-Turing Natural Language Generation (MT-NLG), at 530 billion parameters, for reading comprehension and natural language inference.
“Very large pre-trained language models … appear to be able to make decent predictions when given just a handful of labeled examples,” stated Bernard Koch, a computational social scientist at UCLA, to TechCrunch

Google so far has chosen to keep its LLMs in-house. The company recently described a 540 billion-parameter model called PaLM that aims to achieve state-of-the-art performance across language tasks.
The development costs for LLMs are steep. A 2020 study cited in the TechCrunch account from AI21 Labs estimated the cost to develop a text-generating model with 1.5 billion parameters to be $1.6 million. Running the trained model also costs money, with one estimate putting the cost of running GPT-3 on a single AWS instance at a minimum of $87,000 per year.
The cost to develop GPT-3 was estimated in an account on the blog of Hugging Face, a company with a lab in France developing open LLMs, to be close to $100 million. Given that few organizations could marshal such resources, the question is, who are the LLMs for?
“For all its engineering brilliance, training Deep Learning models on GPUs is a brute force technique,” stated Julien Simon, chief evangelist of Hugging Face, author of the post.
For pragmatic guidance, Simon made the following suggestions for companies exploring the potential of AI with LLMs: research what pre-trained models are available to deliver the accuracy you need;” fine-tune an existing model to use less data, conduct faster experiments, and use fewer resources; use a cloud-based infrastructure; and optimize your model.
Tech Companies Eye Growth Opportunities Pose by LLMs
Have no double that the growth of LLMs is a huge growth opportunity for tech companies. Nvidia, for example, recently announced a new service, ‘Hopper,’ or more specifically, Hopper H100 Tensor Core GPU. The promise is to deliver 3.5 times the power efficiency of the previous generation A100 GPUs by using five times fewer server nodes, resulting in a total cost of ownership that is three times lower than the previous generation, according to a recent account in Fierce Electronics.
“We see large language models exploding everywhere,” stated Ian Buck, general manager and vice president of accelerated computing at Nvidia, in the Fierce account. “They are being used for things outside of human language like coding and helping software developers write software faster, more efficiently, and with fewer errors…. We’re also seeing these models applied to the language of chemistry and biology to predict the properties of materials or for drugs. Hopper was explicitly designed to help accelerate these kinds of models.”
Moreover, “Large language models hold the potential to transform every industry,” stated Jensen Huang, founder and CEO of Nvidia. “The ability to tune foundation models puts the power of LLMs within reach of millions of developers, who can now create language services and power scientific discoveries without needing to build a massive model from scratch.”
Amazon Web Services, Google, Microsoft Azure, HP, Dell, and Cisco Systems, set to offer in coming months their own products and services that will leverage the new Nvidia chip architecture.
Read the source articles and information in VentureBeat, in TechCrunch, on the blog of Hugging Face and in Fierce Electronics.
(Write to the editor here.)