

In the Trenches of Reinforcement Learning with Human Feedback
Subcontractors in faraway countries hired to fact-check and moderate content under time pressure for low wages; tempering political bias also on the agenda

By John P. Desmond, Editor, AI in Business
It might be ludicrous for a boss to tell hired content moderation workers to fact-check the entire internet, make some suggestions, and do it all in a tight time frame for a fairly low wage. But instructions along those lines might not be extremely far from the truth.
Google funds thousands of contractors who work at rates as low as $14 an hour to assess whether selected responses of its Bard chatbot are well-sourced and based on evidence, according to a recent account in Bloomberg.
Google contracts with companies including Appen Ltd. and Accenture Plc to employ people who work with minimal training and tight deadlines to try to filter out mistakes and bias in Bard’s responses to queries that can span the range of all human knowledge and creativity. This is what the authors called “the invisible backend of the generative AI boom.”
After OpenAI launched ChatGPT in November, Google reportedly increased the workload and complexity of tasks for the reviewers. In May at Google’s annual I/O conference, Bard was opened up to 180 countries and territories, and experimental AI features were featured in search, email and Google Docs.
Tasks for the contractors included comparing two answers, such as on Florida’s ban on gender-affirming care, and rate them by helpfulness and relevance. The workers are also often asked whether the model’s answers include verifiable evidence. And they are asked to screen responses for harmful or offensive content, based on the worker’s own knowledge or a quick web search, but not a “rigorous fact check.”
The work to screen for harmful or offensive content was described in a recent account from The Guardian. Contractors around the world were hired by Sama, a California-based data annotation services company, which had an agreement with OpenAI in 2021 and 2022. Sama hired 51 moderators in Nairobi, Kenya, to review texts and some images. Many were reported to depict graphic scenes of violence, self-harm and various sexual assaults.
Four of the moderators filed a petition with the Kenyan government calling for an investigation into the working conditions of the reviewers, who said they were not fairly warned about the nature of the work and who experienced trauma and other psychological impacts afterward. The workers were paid between $1.46 and $3.74 per hour, according to the Guardian account. Sama pulled out of the contract eight months early, saying it wished to focus on its core competency.
Content Moderation a Growing Business
To train Bard, ChatGPT and other language models to recognize prompts that would generate harmful materials, the algorithms need to learn from examples of hate speech, violence and sexual abuse. This work is a growing business; the collection and labeling industry is expected to grow to over $14 billion in revenue by 2030, according to Global Data consultants.
Much of the work will be performed thousands of miles from Silicon Valley, in East Africa, India, the Philippines, and even refugees living in Kenya’s Dadaab and Lebanon’s Shatila – camps with a large pool of multilingual workers who are willing to do the work for a fraction of the cost, stated Srravya Chandhiramowuli, a researcher of data annotation at the University of London, to the Guardian.

Many tech companies hire outside contractors to help train AI products and moderate social network content including OpenAI, Meta, Amazon and Apple.
“If you want to ask, what is the secret sauce of Bard and ChatGPT? It’s all of the internet. And it’s all of this labeled data that these labelers create,” stated Laura Edelson, a computer scientist at New York University. “It’s worth remembering that these systems are not the work of magicians–they are the work of thousands of people and their low-paid labor,” she stated.

In a statement, Google said the company does not employ the workers and their suppliers determine the pay and benefits, hours and tasks assigned to the workers.
The contracted workers told Bloomberg they never received any direct communication from Google about the AI-related work; it got filtered through their employer. And they said they do not know where the AI-generated responses they see are coming from, or where their feedback goes.
Emily Bender, a professor of computational linguistics at the University of Washington, said, “The people behind the machine who are tasked with making it be somewhat less terrible … have an impossible job.”

Reinforcement Learning With Human Feedback to Align Values
ChatGPT has been shaped by reinforcement learning with human feedback (RLHF), according to a recent account from Brookings. RLHF uses feedback from human testers to help align LLM outputs with human values. “Of course, there is a lot of human variation in how ‘values’ are interpreted,” stated the authors of the Brookings account. They added, “The RLHF process shapes the model using the views of the people providing feedback, who will inevitably have their own biases.”
OpenAI CEO Sam Altman identified his concern about a major potential source of bias in a recent podcast. “The bias I am most nervous about is the bias of the human feedback raters,” he stated. When he was asked if employees of the company could affect the bias of the system, Altman stated, “One hundred percent.” He referred to the importance of avoiding the “groupthink” bubbles in San Francisco, where OpenAI is based, and in the field of AI in general.
Maybe that’s behind the thinking about using human testers from many parts of the world. Altman is right to be concerned. According to a 2019 report from the AI Now Institute, the field of AI is dominated by white men.
Research Team Measured Political Bias in Major AI Models
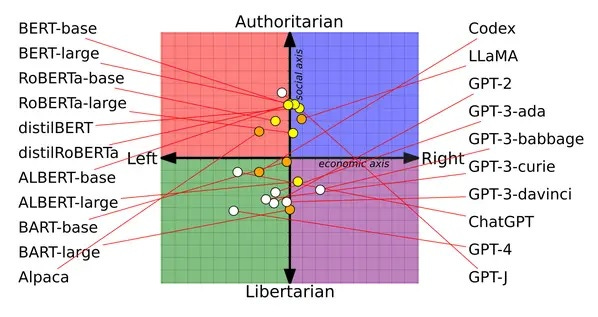
A team of researchers from the University of Washington, Carnegie Mellon University and Xi’an Jiaotong University in Xi'an, Shaanxi, China, set out to measure political bias in major AI language models in a way that could be quantified, according to a recent account in Business Insider.
Each model was subject to a ‘political compass test” that analyzed responses to 62 political statements ranging from “all authority should be questioned” to “mothers may have careers, but their first duty is to be homemakers.” Results were plotted on a political compass graph, which goes from left- to right-learning on one axis and libertarian to authoritarian on the other.
With the authors conceding the method was “far from perfect,” the results showed that of the 14 major language models tested, Open AI’s ChatGPT was the most left-leaning and libertarian. Meta’s LLaMA was found to be the most right-leaning and authoritarian.
In response to a query from Business Insider about the results, a Meta spokesperson said in a statement: "We will continue to engage with the community to identify and mitigate vulnerabilities in a transparent manner and support the development of safer generative AI."
In a March interview with The Information, OpenAI cofounder and president Greg Brockman acknowledged shortcomings of ChatGPT around left-leading political bias. "Our goal is not to have an AI that is biased in any particular direction," Brockman stated. "We want the default personality of OpenAI to be one that treats all sides equally. Exactly what that means is hard to operationalize, and I think we're not quite there."
Read the source articles and information from Bloomberg, The Guardian, Brookings, the AI Now Institute, Business Insider and The Information.
(Write to the editor here; let him know what you would like to read about in AI in Business.)
